
The crucial role of clinical data management (CDM) in a successful clinical trial is well understood, and central to this is the production of quality, accurate and comprehensive clinical data. This is critical for safety and efficacy to meet the standards to pass review by the regulatory authorities.
Modern techniques for CDM are emerging in the application of data science tools and technologies to support data validation and reporting activities. Indeed, at Phastar, our Data Operations group utilises data science techniques by applying novel approaches such as the application of AI and development of visualisations to deliver insights, drive efficiencies and ultimately add value to the clinical trial process.
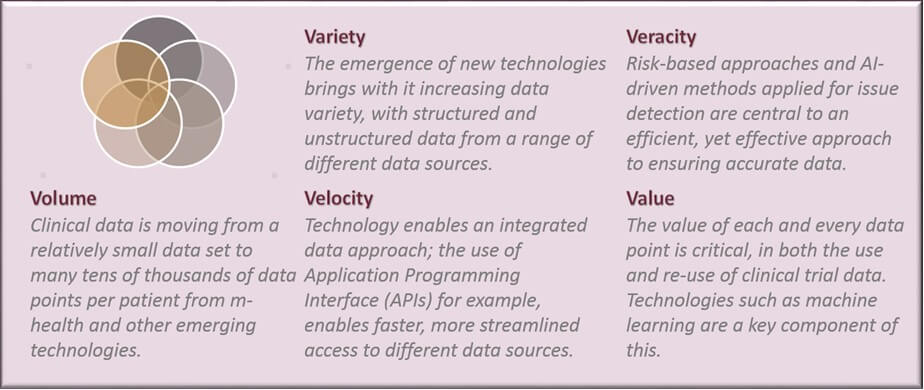
Central to the CDM approach is the consideration of 5 essential data elements; data volume, variety, velocity, veracity and value. Data science techniques support CDM in these different areas through the exploration, application and development of different technologies and approaches.
The alignment of CDM and modern data science techniques at Phastar is delivering value through the development of a guided-review approach to data cleaning activities. Through the application of AI and rule-based approaches, we use data science methods to auto-detect potential data inconsistencies and anomalies. We have explored the potential efficiency gains from such an approach; the vital role of the human expert, particularly where free text is involved; and the progress and challenges integrating such a method into the existing data query process.
The first step was to develop an approach to identify variables and forms that had high number of manual queries on a study. By applying an AI technique to the free-text, queries were grouped into themes, and within each theme, a set of common words appearing in those queries were identified. These themes and associated words enabled the team to understand common issues across and within studies.
Guided by these insights, CDM then identified areas where automation would likely benefit the data cleaning process and a rule-based approach was developed to identify potential data quality issues. Together with the generation of a bespoke interactive dashboard, CDM were able to assess the efficiency gains in such an approach and iteratively improve the method. Ultimately, the system will learn how to automatically identify data anomalies – providing a mechanism to drive increased time and cost efficiencies and empowering CDM to use such technology to their advantage.
At Phastar we are excited by the both the rewards and future potential of aligning data science and CDM and expect to see more applications in the future.


